
readme.md 13 KB
词法分析科学计算器
上一节: https://bbs.125.la/forum.php?mod=viewthread&tid=14705096 源代码 git: http://gogs.mkyr.fun:99/myuan/elang
目标
本节的目标是实现包含一些初等函数的计算器解析器, 允许输入的例子如下:
# 允许以#开始写注释, #到行尾的将被忽略
1 + sin(degree(30)) # 角度制的30度
3 * log(10, 100) # 以10为底, 取100的对数
4 / ((2-3) / (4/2)) # 当然仍然还有括号可以用
代码流程
上一节中实现功能时边读入边解析和计算, 如果按照这样的逻辑完成本节的目标, 代码将会冗长又固执, 难以阅读和修改. 本节的代码清晰地分为了两个部分:
- 词法分析, 将文本拆成不同的词单元, 这里靠正则表达式拆
- 语法分析, 根据不同的模式分析语法生成语法树, 上文中语法大致可以分为
2.1 a + b 中缀表达式
2.2 f(a, b, c) 函数调用式
2.3 a * (b + c) / (f(a) + 2) 带括号的前二者
词法分析
此处的「词」是一个泛指, 意为某些同类字的集合, 如「12334.235」是「数字和小数点」的集合是词, 「sin」是「字母」的集合是词, 「# 注释文本」也是词.
这里定义了一些词类型
.版本 2
.常量 词类型枚举
.常量 词类_数字, "1"
.常量 词类_整数部分, "2"
.常量 词类_小数部分, "3"
.常量 词类_标识符, "4"
.常量 词类_算符, "5"
.常量 词类_括号, "6"
.常量 词类_注释, "7"
.常量 词类_逗号, "8"
.常量 词类_空格, "9"
.常量 词类型枚举数量, "9"
词类_整数部分和词类_小数部分是为了迁就小数匹配, 词法分析的时候是跳过这两个的. 词法分析的时候逻辑很简单, 伪代码大约是:
对于每一个词类
如果 是整数部分 或 小数部分
到循环尾
end
如果 正则匹配对当前剩余文本匹配成功
记录匹配结果和类型
文本游标往右走匹配结果那么长
跳出循环
end
end
至于匹配, 是用正则表达式做的, 这一部分当然也能手写, 但是太无聊了, 手写留到下部一份词法分析吧, 那地方更有价值一些. 正则如下:
.版本 2
.支持库 RegEx
' 可能带°的数字 (\d+)(\.\d+)*[°]{0,1}
' 标识符 [a-zA-ZΑ-Ωα-ω_][a-zA-ZΑ-Ωα-ω0-9_]*
' 算符 [\+\-\*\/\^]
' 括号 [\(\)]
' 注释 \#.+
' 逗号 ,
' 易语言的正则表达式没办法用\u, 也没办法写希腊字母, 也没办法写「°」, 因此去掉希腊字母和「°」, 加上空白, 合起来就是这样的
.如果真 (正则.是否为空 ())
正则.创建 (“((\d+)(\.\d+)*)|([a-zA-Z_][a-zA-Z0-9_]*)|([\+\-\*\/\^])|([\(\)])|(\#.+)|([,])|[ ]+$”, )
' ________________m1______________ -> 数字
' ____________ m2___m3____________ -> 数字的整数和小数部分
' __________________________________________m4___________ -> 标识符 包含英文字母和希腊字母 只能以字母或下划线开头, 之后可以是数字或字母下划线
' _______________________________________________________________m5______ -> 算符, +-*/^
' __________________________________________________________________________m6___ -> 括号
' _________________________________________________________________________________m7___ -> 注释
' _______________________________________________________________________________________m8___ -> 逗号
这样一趟后就得到了这样的结果
> 词法分析 sin(x) + cos(pi * y) - ln(x) * 123.456 # 注释
用时 0ms
当前类型: 4, 内容: sin
当前类型: 6, 内容: (
当前类型: 4, 内容: x
当前类型: 6, 内容: )
当前类型: 5, 内容: +
当前类型: 4, 内容: cos
当前类型: 6, 内容: (
当前类型: 4, 内容: pi
当前类型: 5, 内容: *
当前类型: 4, 内容: y
当前类型: 6, 内容: )
当前类型: 5, 内容: -
当前类型: 4, 内容: ln
当前类型: 6, 内容: (
当前类型: 4, 内容: x
当前类型: 6, 内容: )
当前类型: 5, 内容: *
当前类型: 1, 内容: 123.456
当前类型: 7, 内容: # 注释
----
>
语法树设计
语法树通常没有定型, 需因地制宜设计. 数学表达式通常可以视为一个纯的无求值顺序问题的语言. 可以做如下规约:
0 ± x -> ±(0, x)
x ± 0 -> ±(x, 0)
a + b -> +(a, b)
12345 -> +(12345, 0)
这样的话所有的计算表达式都可以写作 函(函甲, 函乙, 函丙, 函丁...)
函: 指函数
那么语法树的每一个节点应当包含如下信息
- 原始文本, debug用
- 函数名
- 参数数组, 类型为节点
- 父节点, 类型为节点
但是很遗憾, 这样的代码会报递归定义错误, 我又没找到怎么把一个指针重新解释成某个自定义类型等我开始扩展易语言语法的时候首先要处理这个事情, 那只能自己申请内存管理数据了, 按C的写法数据结构定义如下:
{
char 函数名[40], // 定长40, 再长不支持了
int32_t 参数量, //
int32_t 参数数组容量, // 参数数组指针后有多大容量, 按照每次*2扩充
uint64_t *参数数组指针, // 按长整数, 未来迁移到x64时兼容
uint64_t *父节点指针, // 该节点的父节点
}
// 此结构单个长度为 40+4+4+8+8 = 64 字节
内存结构如图: 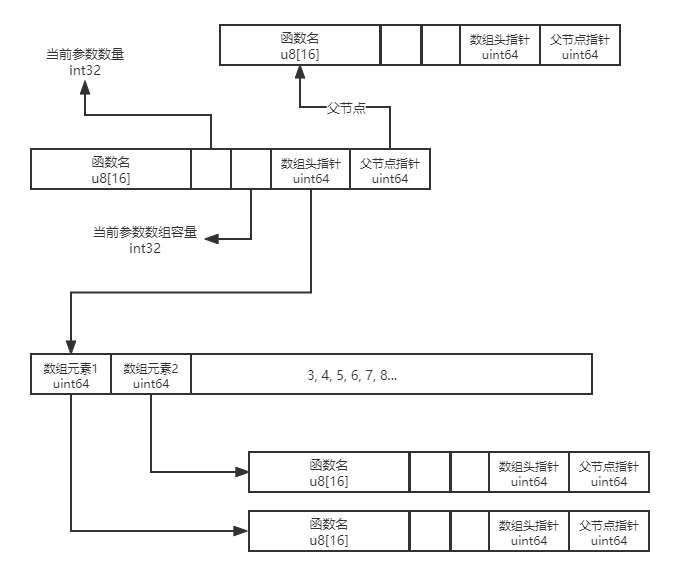
这部分大概花了我三四个小时去写和 debug, 跟写汇编有一拼了. 终于可以开始写递归下降器了.
递归下降
我不觉得我谈论递归下降能比网上的其他教程更好, 随便找了两个参考链接.
额外阅读:
- 递归下降器
- - https://zhuanlan.zhihu.com/p/31271879
- - https://zh.wikipedia.org/wiki/%E9%80%92%E5%BD%92%E4%B8%8B%E9%99%8D%E8%A7%A3%E6%9E%90%E5%99%A8
接下来将假设你有基础的相关知识了. 考虑合规的表达式要么是 f(args) x + y, 要么是二者在括号内外通过算符连接, 因此给出如下定义
# 尖括号内是词类型, 大括号内是语法
# * 与正则表达式内星号含义相同, 指匹配0或任意次 ((女装)*)
# + 与正则表达式内星号含义相同, 指匹配至少1次
# | 表 或.
表达式 ::= 加后表达式 (("+" | "-") 加后表达式)*
加后表达式 ::= 因子 (("*" | "/") 因子)*
因子 ::= 左括号 表达式 右括号 | 函数 | 数字
函数 ::= 标识符 左括号 (表达式 (逗号 表达式)*){0,1} 右括号
光写出来构造还是蛮简洁的, 匹配表达式时可以沿着表达式->加后表达式->因子->函数->表达式走, 这就是递归下降里的递归含义, 而下降则是指自顶向下慢慢解析. 如果你足够敏锐, 一定能意识到这个流程可能出现无限循环, 这就是左递归问题, 好在上面所提到的数学表达式是LL(1)文法(从左往右每次多看1个词就可以确定究竟是什么), 脑子不糊涂一般不会写出来无限循环. 对于更复杂的情况, 可以上LL(k)解析器, 尽量多看几个. 不过还有一些其他处理方法, 后面再提.
加减乘除分析
将 git 历史切换到 8259cc94337f4409d6a6fe6e4d17eedcd7685fc4 完成加减的词法分析, 可以看到我当时的中间过程, 至此程序可以使用递归下降方法来区分加减乘除的优先级, 而不需要像第一节一样手动给出一个表来指定优先级
> 语法分析 1*2*3-4*5*6-7*8/9+10*11*12
用时 0ms
根 | 基地址: 7f5250 | 参数数量: 1 | 参数容量: 8 | 参数数组地址: 7f3af0
+ | 基地址: 7f7e88 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f85c0
- | 基地址: 7f76f8 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f7ee0
- | 基地址: 7f6f68 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f7750
* | 基地址: 7f6ca8 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f6e60
* | 基地址: 7f6a98 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f6d00
1 | 基地址: 7f6938 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f6990
2 | 基地址: 7f6b48 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f6ba0
3 | 基地址: 7f6d58 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f6db0
* | 基地址: 7f7438 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f75f0
* | 基地址: 7f7228 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f7490
4 | 基地址: 7f70c8 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f7120
5 | 基地址: 7f72d8 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f7330
6 | 基地址: 7f74e8 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f7540
/ | 基地址: 7f7bc8 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f7d80
* | 基地址: 7f79b8 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f7c20
7 | 基地址: 7f7858 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f78b0
8 | 基地址: 7f7a68 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f7ac0
9 | 基地址: 7f7c78 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f7cd0
* | 基地址: 7f8358 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f8510
* | 基地址: 7f8148 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 7f83b0
10 | 基地址: 7f7fe8 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f8040
11 | 基地址: 7f81f8 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f8250
12 | 基地址: 7f8408 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 7f8460
>
这个输出的阅读方式为: 找到两个相邻的叶结点, 其共同父节点即算符, 如此组成的新节点可以与其相邻节点加上父节点组合. 有没有一点正经语言的感觉了?
括号处理
将 git 历史切换到 55e0ea657e8b5f789574a1888415477901b32fdd 添加括号处理, 可以发现只写了寥寥几新行, 就完成了括号的处理, 而且非常符合直觉.
递归下降器完结
> 语法分析 1 -( sin(2222, 4444, tan(5555) + arctan(6666)) - cos(3333) )* 4
用时 1ms
根 | 基地址: 62bf68 | 参数数量: 1 | 参数容量: 8 | 参数数组地址: 62c548
- | 基地址: 62d880 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 632e28
1 | 基地址: 62c480 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 62cf98
* | 基地址: 632bc0 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 632d78
括号 | 基地址: 62c3e8 | 参数数量: 1 | 参数容量: 8 | 参数数组地址: 632b68
- | 基地址: 6308d0 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 632ab8
sin | 基地址: 630ae0 | 参数数量: 3 | 参数容量: 8 | 参数数组地址: 630b38
2222 | 基地址: 630f90 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 630fe8
4444 | 基地址: 631320 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 631378
+ | 基地址: 631610 | 参数数量: 2 | 参数容量: 8 | 参数数组地址: 631dd8
tan | 基地址: 631770 | 参数数量: 1 | 参数容量: 8 | 参数数组地址: 6317c8
5555 | 基地址: 631c20 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 631c78
arctan | 基地址: 631f30 | 参数数量: 1 | 参数容量: 8 | 参数数组地址: 631f88
6666 | 基地址: 6323e0 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 632438
cos | 基地址: 632540 | 参数数量: 1 | 参数容量: 8 | 参数数组地址: 632598
3333 | 基地址: 632900 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 632958
4 | 基地址: 632c70 | 参数数量: 0 | 参数容量: 8 | 参数数组地址: 632cc8
鸣谢
感谢 e2txt 工具, 使得我可以按纯文本保存代码, 添入版本控制
其他
本节代码使用 git 组织, 每一个里程碑我都会创建一个 commit, 你可以通过 git 回溯来分步查看我的编码过程. 如果你不会 git, 可以下载一个 github desktop, 可以直接在 GUI 上看到各个 commit 的内容.
细微之处的东西在代码的注释或者调试输出里.
在 e2txt 工具的关于里我发现了一段「易语言源码及内部关系极其复杂,代码的生成过程跟编译器类似。由于易语言不具备面向对象的特性,所以本项目开发过程中耗费了大量的精力处理语法树和对象关系的维护。」, 同是天涯沦落人, 为了表达语法树我也自己手动控制内存搞了一大堆事情.
本文是边写代码边写的, 中间可能有些地方改了代码但是并没有反应到文本里, 如果你发现了问题, 请指出.
额外阅读
下节预告
- 使用易语言实现的计算器的虚拟机
- 在JavaScript里实现的同样功能的解析器和虚拟机
本节代码仍然使用纯的易语言做文本分析, 但是如果你详细读了这份代码, 会发现大量逻辑上的重复, 之后我将使用 JavaScript 的 peggyjs 库来重新做这件事, 同时, 如果你认真读了本节代码, 你也可以轻松读懂 peggyjs 的大部分东西. 为什么用 JavaScript 的库? 因为易语言没人做这种DSL. 另外就是 JavaScript 的话可以放到浏览器上去分析易语言语法啦, 也就有机会运行到浏览器里去了. 那么我现在写的命令行上的分析程序也能上浏览器了.
不过严格来说, 正则表达式也是 DSL, 因此用了正则表达式就不算是纯易语言了.