
system.md 14 KB
Go 系统概述
基本类型
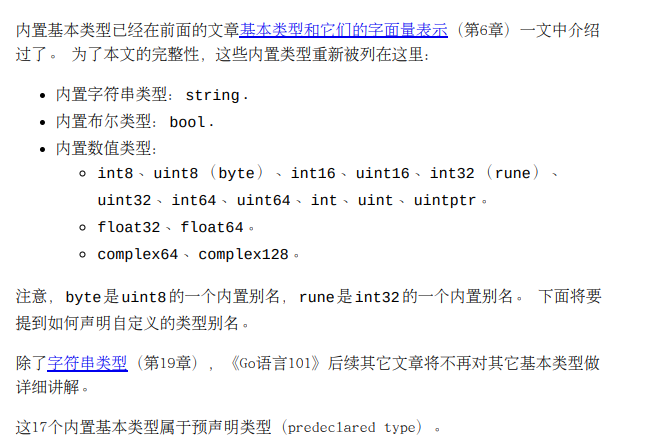
组合类型
数组长度固定、切片动态长度
1| // 假设T为任意一个类型,Tkey为一个支持比较的类型。
2|
3| *T // 一个指针类型
4| [5]T // 一个元素类型为T、元素个数为5的数组类型
5| []T // 一个元素类型为T的切片类型
6| map[Tkey]T // 一个键值类型为Tkey、元素类型为T的映射类型
7|
8| // 一个结构体类型
9| struct {
10| name string
11| age int
12| }
13|
14| // 一个函数类型
15| func(int) (bool, string)
16|
17| // 一个接口类型
18| interface {
19| Method0(string) int
20| Method1() (int, bool)
21| }
22|
23| // 几个通道类型
24| chan T
25| chan<- T
26| <-chan T
Go 对面向对象编程的支持
- 方法(22)
- 实现(23)
- 类型内嵌(24)
Go对泛型的支持
- 泛型(26)
指针
指针类型和值
在Go中,一个无名指针类型的字面形式为*T,其中T为一个任意类型。类型T称为 指针类型*T的基类型(base type)。 如果一个指针类型的基类型为T,则我们可 以称此指针类型为一个T指针类型。
1| *int // 一个基类型为int的无名指针类型。
2| **int // 一个多级无名指针类型,它的基类型为*int。
3|
4| type Ptr *int // Ptr是一个具名指针类型,它的基类型为int。
5| type PP *Ptr // PP是一个具名多级指针类型,它的基类型为Ptr。
指针类型的零值的字面量用预声明的nil来表示。nil指针(常称为空指针)中不存储任何地址。
如果一个指针类型的基类型为T,则此指针类型的值只能存储类型为T的值的地址。
如何获取一个指针值
- 假设T是任一类型,调用new(T)返回一个类型为*T的指针值。存储在返回指针值所表示的地址处的值是T的零值。
可以用前置取地址操作符&来获取一个可寻址值的地址。 对于一 个类型为T的可寻址的值t,我们可以用&t来取得它的地址。&t的类型为 *T
//有关解引用 值传递 1| package main 2| 3| import "fmt" 4| 5| func main() { 6| p0 := new(int) // p0指向一个int类型的零值 7| fmt.Println(p0) // (打印出一个十六进制形式的地址) 8| fmt.Println(*p0) // 0 9| 10| x := *p0 // x是p0所引用的值的一个复制。 11| p1, p2 := &x, &x // p1和p2中都存储着x的地址。 12| // x、*p1和*p2表示着同一个int值。 13| fmt.Println(p1 == p2) // true 14| fmt.Println(p0 == p1) // false 15| p3 := &*p0 // <=> p3 := &(*p0) 16| // <=> p3 := p0 17| // p3和p0中存储的地址是一样的。 18| fmt.Println(p0 == p3) // true 19| *p0, *p1 = 123, 789 20| fmt.Println(*p2, x, *p3) // 789 789 123 21| 22| fmt.Printf("%T, %T \n", *p0, x) // int, int 23| fmt.Printf("%T, %T \n", p0, p1) // *int, *int 24| }
为什么需要指针
看懂就行啦 其实就是创建修改了指针副本,但指针副本也是指向原指针的地址值,对副本的修改也会对原指针的地址值生效
1| package main
2|
3| import "fmt"
4|
5| func double(x *int) {
6| *x += *x
7| x = nil // 此行仅为讲解目的
8| }
9|
第15章:指针
123
10| func main() {
11| var a = 3
12| double(&a)
13| fmt.Println(a) // 6
14| p := &a
15| double(p)
16| fmt.Println(a, p == nil) // 12 false
17| }
Go中返回一个局部变量的地址是安全的
Go支持垃圾回收,所以一个函数返回其内声明的局部变量的地址是 绝对安全的。比如:
1| func newInt() *int {
2| a := 3
3| return &a
4| }
指针比较赋值、要考虑类型
Go指针值是支持(使用比较运算符==和!=)比较的。 但是,两个指针只有在下列任一条件被满足的时候才可以比较:
- 这两个指针的类型相同。
- 其中一个指针可以被隐式转换为另一个指针的类型。换句话说,这两个指针的 类型的底层类型必须一致并且至少其中一个指针类型为无名的(考虑结构体字 段的标签)。
- 其中一个并且只有一个指针用类型不确定的nil标识符表示。
结构体
结构体类型和其字面量表现形式
一个结构体类型的尺寸为它的所有字段的(类型)尺寸之和加上一些填充字节的数目。编译器会在一个结构体值的两个相邻字段之间填充一些字节来保证一些字段的地址总是某个整数的倍数。
结构体值的赋值
1| func f() {
2| book1 := Book{pages: 300}
3| book2 := Book{"Go语言101", "老貘", 256}
4|
5| book2 = book1
6| // 上面这行和下面这三行是等价的。
7| book2.title = book1.title
8| book2.author = book1.author
9| book2.pages = book1.pages
10| }
结构体字段的可寻址性
如果一个结构体值是可寻址的,那它的字段也是可寻址的;反之,不可寻址的结构体值的字段也是不可寻址的。不可寻址的字段的值是不可更改的。所有组合的字面量都是不可寻址的。
在字段选择器中,属主结构体值可以是指针,它将被隐式解引用
结构体值的比较
可以比,但没必要
结构体值的类型转换
两个类型分别为S1和S2的结构体值只有在S1和S2的底层类型相同(忽略掉字段标 签)的情况下才能相互转换为对方的类型。 特别地,如果S1和S2的底层类型相同 (要考虑字段标签)并且只要它们其中有一个为无名类型,则此转换可以是隐式 的。
值部
Go类型分为两大类别
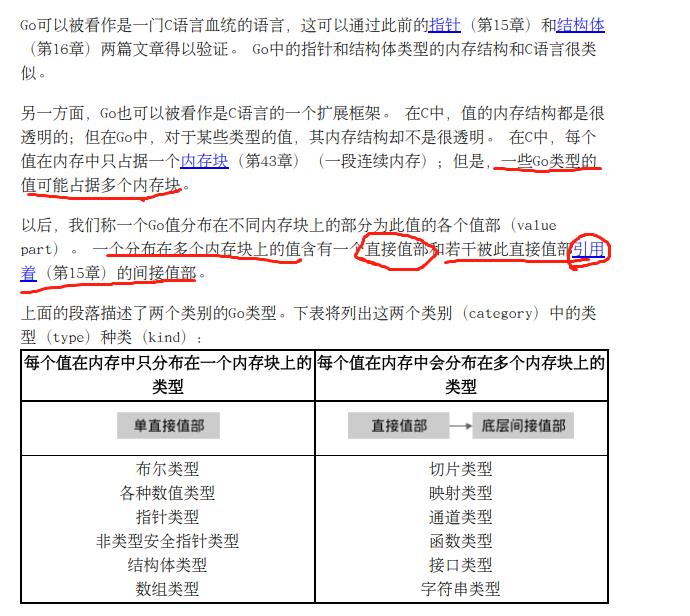
关于术语“引用类型”和“引用值”
“引用”这个术语在Go社区中使用得有些混乱。很多Go程序员在Go编程中可能由此 产生了一些困惑。 一些文档或者网络文章,包括一些官方文档 (https://golang.google.cn/doc/faq#references),把“引用”(reference) 看作是“值”(value)的一个对立面。 《Go语言101》强烈不推荐这种定义。在这 一点上,本人不想争论什么。这里仅仅列出一些肯定错误地使用了“引用”这个术 语的例子:
- 在Go中,只有切片、映射、通道和函数类型属于引用类型。 (如果我们确实 需要引用类型这个术语,那么我们不应把其它指针持有者类型排除在引用类型 之外。)
- 一些函数调用的参数是通过引用来传递的。 (对不起,在Go中,所有的函数 调用的参数都是通过值复制直接值部的方式来传递的。)
我并不是想说引用类型这个术语在Go中是完全没有价值的, 我只是想表达这个术语 是完全没有必要的,并且它常常在Go的使用中导致一些困惑。我推荐使用指针持有者类型来代替这个术语。 另外,我个人的观点是最好将引用这个词限定到只表示值 之间的关系,把它当作一个动词或者名词来使用,永远不要把它当作一个形容词来 使用。 这样将在使用Go的过程中避免很多困惑。
数组、切片和映射(没全看懂)
切片的长度和容量并不是一个概念
切片长度不定、数组长度固定
len(map类型) = 0
映射和切片的复制,共享底层元素,它们的长 度和容量也相等。 区别在于切片的复制,其中一个切片如果改变了长度或者容量,此变化不会体现到另一个切片中 当一个数组被赋值给另一个数组,所有的元素都将被从源数组复制到目标数组。赋 值完成之后,这两个数组不共享任何元素
添加和删除容器元素
append内置函数,需要理解。
对于map类型m;
m[k] = e //添加 k,e 键值对
delete(m, k) //删除m的k键值对;即使m为nil,也不会产生panic
对于切片类型;
切片类型的值传递要慎用
1| package main
2|
3| import "fmt"
4|
5| func main() {
6| s0 := []int{2, 3, 5}
7| fmt.Println(s0, cap(s0)) // [2 3 5] 3
8| s1 := append(s0, 7) // 添加一个元素
9| fmt.Println(s1, cap(s1)) // [2 3 5 7] 6
10| s2 := append(s1, 11, 13) // 添加两个元素
11| fmt.Println(s2, cap(s2)) // [2 3 5 7 11 13] 6
12| s3 := append(s0) // <=> s3 := s0
13| fmt.Println(s3, cap(s3)) // [2 3 5] 3
14| s4 := append(s0, s0...) // 以s0为基础添加s0中所有的元素
15| fmt.Println(s4, cap(s4)) // [2 3 5 2 3 5] 6
16|
17| s0[0], s1[0] = 99, 789
18| fmt.Println(s2[0], s3[0], s4[0]) // 789 99 2
19| }
make函数
可以用make创建切片和映射,数组不行
1| make(S, length, capacity)
2| make(S, length) // <=> make(S, length, length)
new函数创造容器值
到内置new函数可以用来为一个任 何类型的值开辟内存并返回一个存储有此值的地址的指针。 用new函数开辟出来的值均为零值。因为这个原因,new函数对于创建映射和切片值来说没有任何价值。
6| m := *new(map[string]int) // <=> var m map[string]int
7| fmt.Println(m == nil) // true
8| s := *new([]int) // <=> var s []int
9| fmt.Println(s == nil) // true
10| a := *new([5]bool) // <=> var a [5]bool
11| fmt.Println(a == [5]bool{}) // true
映射的整体修改是可以的,但是部分修改不被允许,但可读
1| package main
2|
3| import "fmt"
4|
5| func main() {
6| type T struct{age int}
7| mt := map[string]T{}
8| mt["John"] = T{age: 29} // 整体修改是允许的
9| ma := map[int][5]int{}
10| ma[1] = [5]int{1: 789} // 整体修改是允许的
11|
12| // 这两个赋值编译不通过,因为部分修改一个映射
13| // 元素是非法的。这看上去确实有些反直觉。
14| /*
15| ma[1][1] = 123 // error
16| mt["John"].age = 30 // error
17| */
18|
19| // 读取映射元素的元素或者字段是没问题的。
20| fmt.Println(ma[1][1]) // 789
21| fmt.Println(mt["John"].age) // 29
22| }
从数组或切片取子切片
一个比较难理解的栗子
1| package main
2|
3| import "fmt"
4|
5| func main() {
6| a := [...]int{0, 1, 2, 3, 4, 5, 6}
7| s0 := a[:] // <=> s0 := a[0:7:7]
8| s1 := s0[:] // <=> s1 := s0
9| s2 := s1[1:3] // <=> s2 := a[1:3]
10| s3 := s1[3:] // <=> s3 := s1[3:7]
11| s4 := s0[3:5] // <=> s4 := s0[3:5:7]
12| s5 := s4[:2:2] // <=> s5 := s0[3:5:5]
13| s6 := append(s4, 77)
14| s7 := append(s5, 88)
15| s8 := append(s7, 66)
16| s3[1] = 99
17| fmt.Println(len(s2), cap(s2), s2) // 2 6 [1 2]
18| fmt.Println(len(s3), cap(s3), s3) // 4 4 [3 99 77 6]
19| fmt.Println(len(s4), cap(s4), s4) // 2 4 [3 99]
20| fmt.Println(len(s5), cap(s5), s5) // 2 2 [3 99]
21| fmt.Println(len(s6), cap(s6), s6) // 3 4 [3 99 77]
22| fmt.Println(len(s7), cap(s7), s7) // 3 4 [3 4 88]
23| fmt.Println(len(s8), cap(s8), s8) // 4 4 [3 4 88 66]
24| }
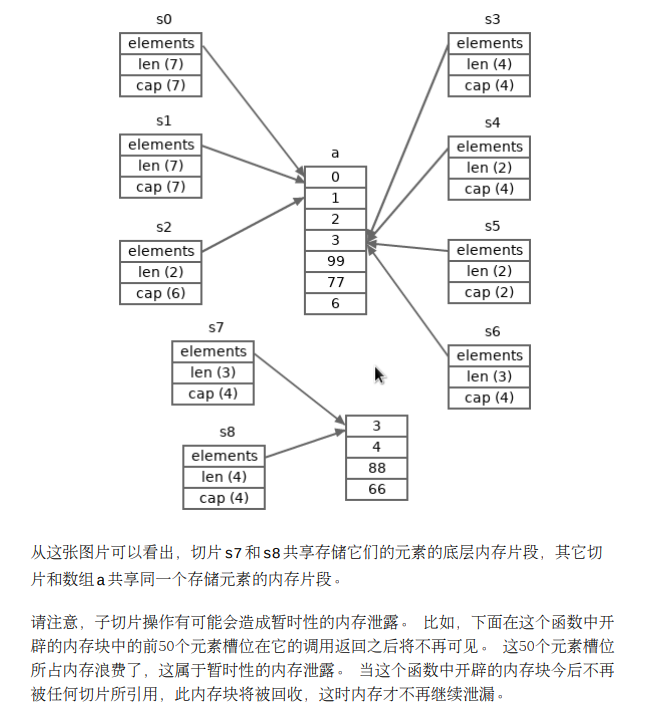
1| func f() []int {
2| s := make([]int, 10, 100)
3| return s[50:60]
4| }
在上面这个函数中,子切片表达式的起始下标(50)比 s 的长度(10)要大,这是允许的。
遍历
遍历一个 nil 映射或者 nil 切片是允许的。这样的遍历可以看作是一个空操作。
一些关于遍历映射条目的细节:
- 映射中的条目的遍历顺序是不确定的
- 遍历映射的过程中,如果一个还没被遍历到的条目被删除了,则此条目保证不会被遍历出来
- 遍历过程中,一个新的条目被加入此映射,则此条目并不保证在此遍历过程中被遍历出来
如果确保没有其它协程操纵一个映射 m , 则下面代码保证清空 m 中所有条目
1| for key := range m {
2| delete(m, key)
3| }
也可以用传统的for循环来遍历
1| for i := 0; i < len(anArrayOrSlice); i++ {
2| element := anArrayOrSlice[i]
3| // ...
4| }
上述各种容器操作内部都未同步
在没有协程修改一个容器值和它的元素的时候,多个协程并发读取此容器值和它的元素是安全的;但是并发修改同一个容器值是不安全的。不使用并发同步技术而并发修改同一个容器值将会造成数据竞争。
字符串
内部结构
1| type _string struct {
2| elements *byte // 引用着底层的字节
3| len int // 字符串中的字节数
4| }
- 使用内置函数len获取一个字符串的长度(此字符串中存储的字节数)
- 使用容器元素索引语法aString[i]获取aString中的第i个字节。表达式aString[i]是不可寻址的。即aString[i]不可被修改
- 使用子切片语法aString[start:end]获取aString的一个子字符串。start和end均为aString中存储的字节的下标
对于标准编译器来说,字符串的赋值完成后,此复制的目标值和源值将和基础字符串aString共享一部分底层字节
当一个字符串被转换为一个字节切片时,结构切片中的底层字节序列是此字符串中存储的字节序列的一份深复制;当一个字节切片被转换为一个字符串时,此字节切片中的字节序列也将被深复制到结果字符串中。字符串和字符接片是不能共享底层字节序列的
字符串、切片类型转换
1| package main
2|
3| import (
4| "bytes"
5| "unicode/utf8"
6| )
7|
8| func Runes2Bytes(rs []rune) []byte {
9| n := 0
10| for _, r := range rs {
11| n += utf8.RuneLen(r)
12| }
13| n, bs := 0, make([]byte, n)
14| for _, r := range rs {
15| n += utf8.EncodeRune(bs[n:], r)
16| }
17| return bs
18| }
19|
20| func main() {
21| s := "颜色感染是一个有趣的游戏。"
22| bs := []byte(s) // string -> []byte
23| s = string(bs) // []byte -> string
24| rs := []rune(s) // string -> []rune
25| s = string(rs) // []rune -> string
26| rs = bytes.Runes(bs) // []byte -> []rune
27| bs = Runes2Bytes(rs) // []rune -> []byte
28| }