|
|
@@ -4,7 +4,7 @@
|
|
|
|
|
|
### MYSQL 基本架构
|
|
|
|
|
|
-
|
|
|
+
|
|
|
|
|
|
存储引擎的选择,默认,innodb
|
|
|
|
|
|
@@ -69,6 +69,8 @@ binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给
|
|
|
|
|
|
# 索引
|
|
|
|
|
|
+
|
|
|
+
|
|
|
## mysql B+ 树
|
|
|
|
|
|
**一个表有多少个索引就有多少个B+树,mysql 中的数据都是按顺序保存在 B+ 树上的**(所以说索引本身是有序的)。
|
|
|
@@ -175,11 +177,25 @@ B+树查询效率更高,因为B+树矮更胖,高度小,查询产生的I/O
|
|
|
|
|
|
这就是MySQL使用B+树的原因,就是这么简单!
|
|
|
|
|
|
-## InnoDB 索引模型
|
|
|
+## 数据结构
|
|
|
+
|
|
|
+*索引的出现是为了提高查询效率,但是实现索引的方式却有很多种,所以这里也就引入了索引模型的概念。可以用于提高读写效率的数据结构很多,这里我先给你介绍三种常见、也比较简单的数据结构,它们分别是**哈希表、有序数组和搜索树**。*
|
|
|
+
|
|
|
+搜索树规定其每个节点的键必须大于其左子树中的任何一个键且小于其右子树中的任何一个键
|
|
|
+
|
|
|
+下图中InnoDB 索引模型 B+树 就是属于搜索树
|
|
|
+
|
|
|
+## InnoDB 索引模型
|
|
|
|
|
|
**一个表有多少个索引就有多少个B+树,mysql 中的数据都是按顺序保存在 B+ 树上的**(所以说索引本身是有序的)。
|
|
|
|
|
|
-### 主键索引与非主键索引区别
|
|
|
+### 主键索引与非主键索引区别(回表)
|
|
|
+
|
|
|
+**回到主键索引树搜索的过程,我们称为回表**
|
|
|
+
|
|
|
+主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
|
|
|
+
|
|
|
+非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
|
|
|
|
|
|
```mysq
|
|
|
mysql> create table T(
|
|
|
@@ -207,6 +223,8 @@ index (k))engine=InnoDB;
|
|
|
- 除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。
|
|
|
- 当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
|
|
|
|
|
|
+### 自增主键
|
|
|
+
|
|
|
**自增主键防止页分裂,逻辑删除并非物理删除防止页合并**
|
|
|
|
|
|
为什么说自增主键防止页分裂?
|
|
|
@@ -226,10 +244,73 @@ index (k))engine=InnoDB;
|
|
|
1. 只有一个索引
|
|
|
2. 该索引必须是唯一索引
|
|
|
|
|
|
-经典KV场景,key-value?
|
|
|
+经典KV场景,key-value
|
|
|
|
|
|
这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。(回表
|
|
|
|
|
|
+### 覆盖索引
|
|
|
+
|
|
|
+https://juejin.cn/post/6844903967365791752
|
|
|
+
|
|
|
+```mysql
|
|
|
+
|
|
|
+mysql> create table T (
|
|
|
+ID int primary key,
|
|
|
+k int NOT NULL DEFAULT 0,
|
|
|
+s varchar(16) NOT NULL DEFAULT '',
|
|
|
+index k(k))
|
|
|
+engine=InnoDB;
|
|
|
+
|
|
|
+insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
|
|
|
+```
|
|
|
+
|
|
|
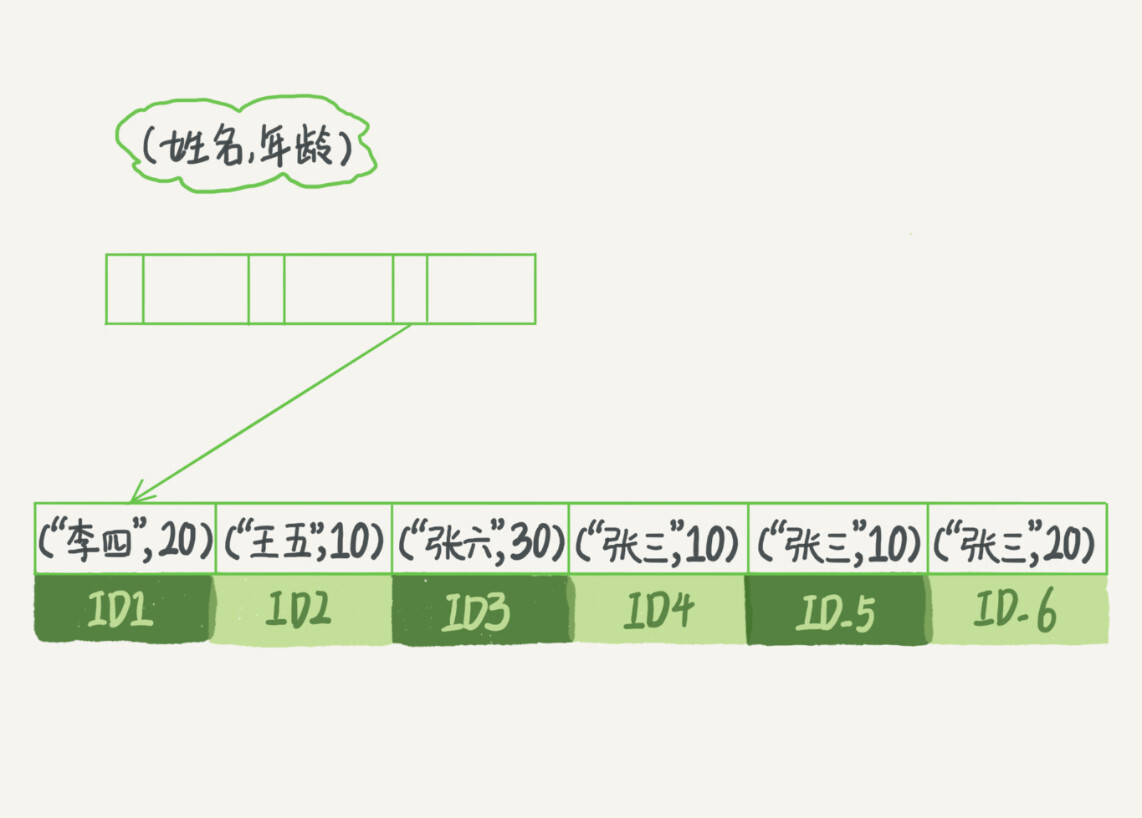
+首先要知道,非主键索引中,存放的是主键。
|
|
|
+主键索引,存放的是所有数据。
|
|
|
+以上图为例,执行`select * from T where k between 3 and 5`时,就会先找索引k ,k=3,然后找到对应的主键,再拿主键去找*
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+再这个栗子中,要查的数据,即 * 只有主键索引中有,所以不得不回表。
|
|
|
+
|
|
|
+如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 是主键已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。
|
|
|
+
|
|
|
+也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。
|
|
|
+
|
|
|
+`select * from T where ID between 100 and 500 ` 这种就不需要回表
|
|
|
+
|
|
|
+**由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。**
|
|
|
+
|
|
|
+### Mysql key 与 index 区别
|
|
|
+
|
|
|
+https://blog.csdn.net/liangwenmail/article/details/86703646
|
|
|
+
|
|
|
+实际使用好像没区别?
|
|
|
+
|
|
|
+*那就把key当index用吧*
|
|
|
+
|
|
|
+### 最左前缀原则 ?
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+有点像ES的那种,综合搜索语法,根据用户的输入,筛选出符合规范的数据,然后找到主键,回表。
|
|
|
+
|
|
|
+### 索引下推
|
|
|
+
|
|
|
+https://blog.csdn.net/luxiaoruo/article/details/106637231
|
|
|
+
|
|
|
+```mysql
|
|
|
+
|
|
|
+mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
|
|
|
+```
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+简单来讲就是,没开启索引下推的话,Server层会把where条件中在组合索引的字段(这里是age)全部推送到引擎层,引擎层根据索引的断桥原则匹配数据拿主键,不管 age 字段 (实际上Server层已经把这个组合索引中的字段推送到引擎层了),直接去查主键,然后再主键的所有行中,看筛选是否成立
|
|
|
+
|
|
|
+开启所有下推的话,Server层会把where条件中在组合索引的字段全部推送到引擎层,引擎层根据索引的断桥原则匹配数据拿主键,然后进行age的筛选,拿到最终匹配的主键关键字再返回Server层,Serer层进行剩余where条俊的筛选,即ismale字段的筛选
|
|
|
+
|
|
|
+**什么情况下才能用索引下推呢?**
|
|
|
+
|
|
|
## 小结
|
|
|
|
|
|
1. 一张表有多个索引
|


{kind=link}
{kind=link}

{kind=link}
